Motivation
Accurately evaluating the performance of large language models (LLMs) is crucial before large-scale deployment. Human evaluation remains the gold standard, but this approach demands substantial time and financial resources. It may also diminish user experience when conducted with active system users,
Synthetic evaluation , on the other hand, generates annotations using a reward model or LLM (e.g., GPT-4). Though reducing the need for extensive human involvement, synthetic evaluators can not perfectly reflect human preference and often introduce bias, undermining the evaluation reliability.
In this work, we propose Control Variates Evaluation to integrate human and synthetic feedback, mitigating reliance on human annotations while maintaining unbiased evaluations.
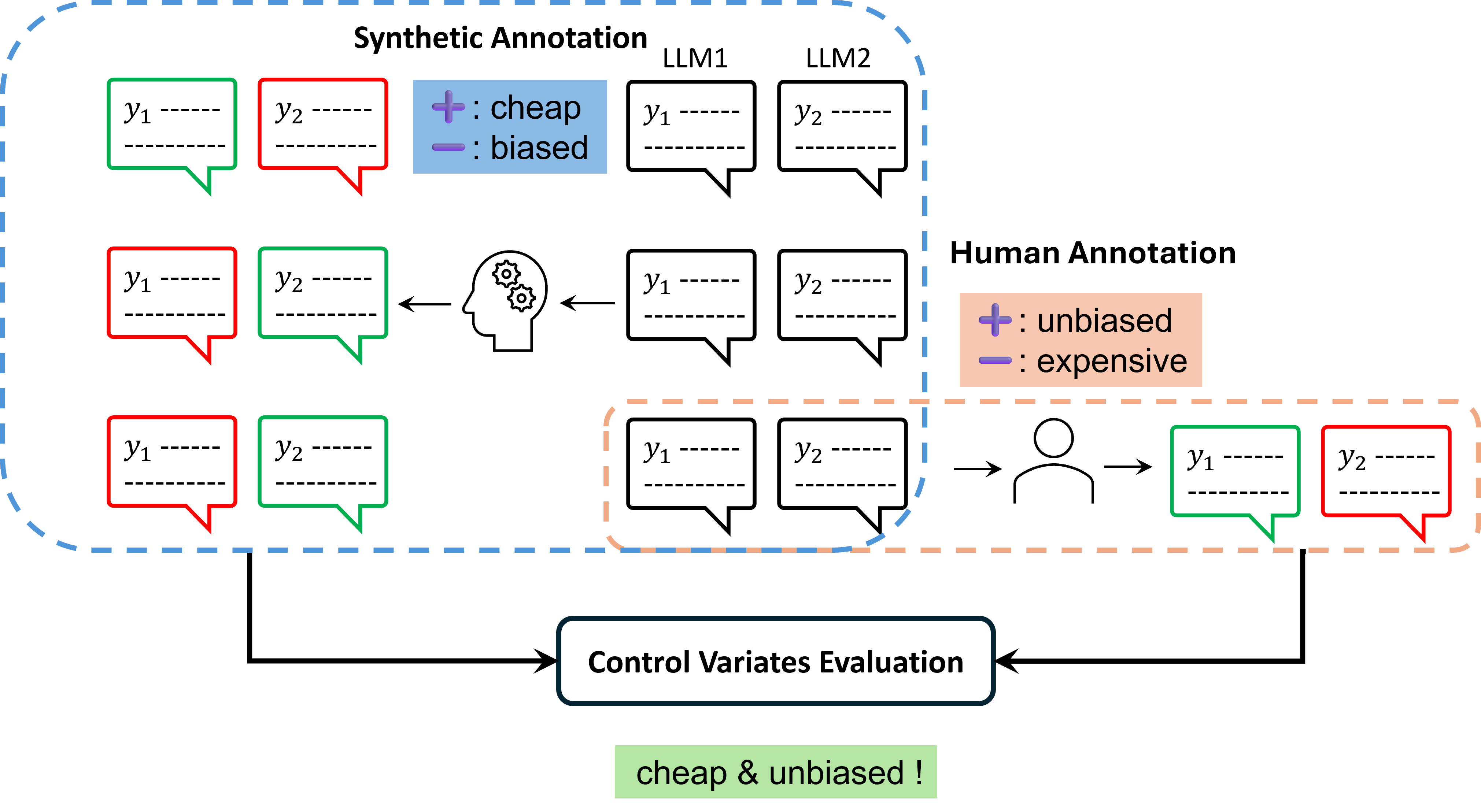

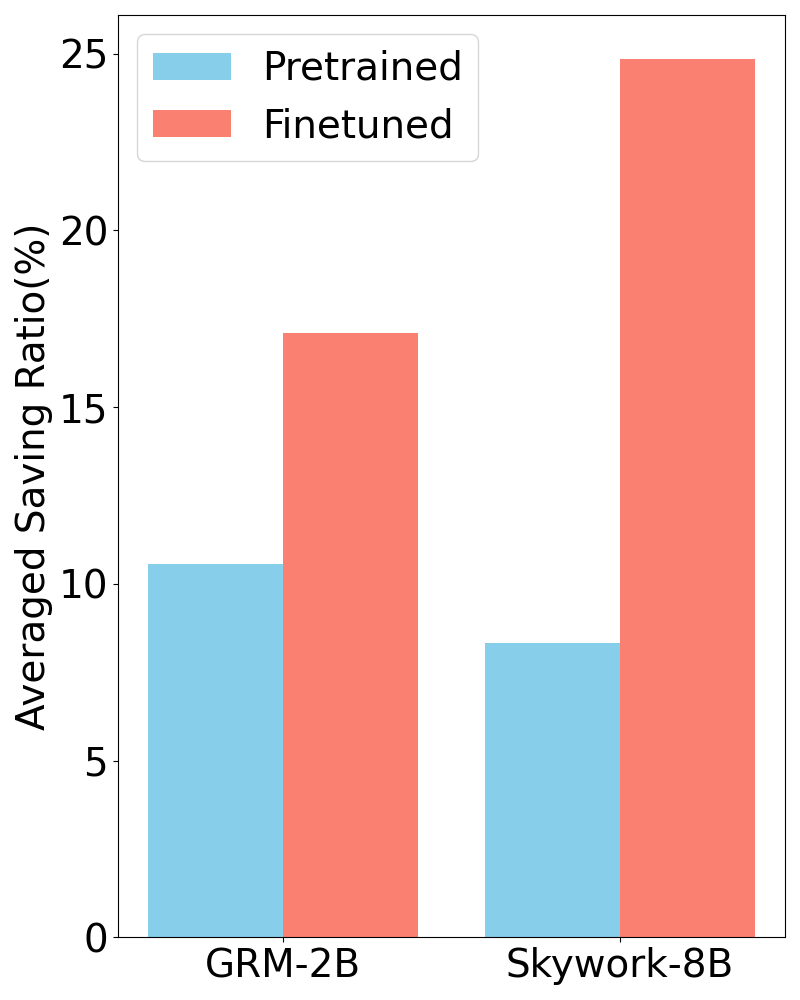
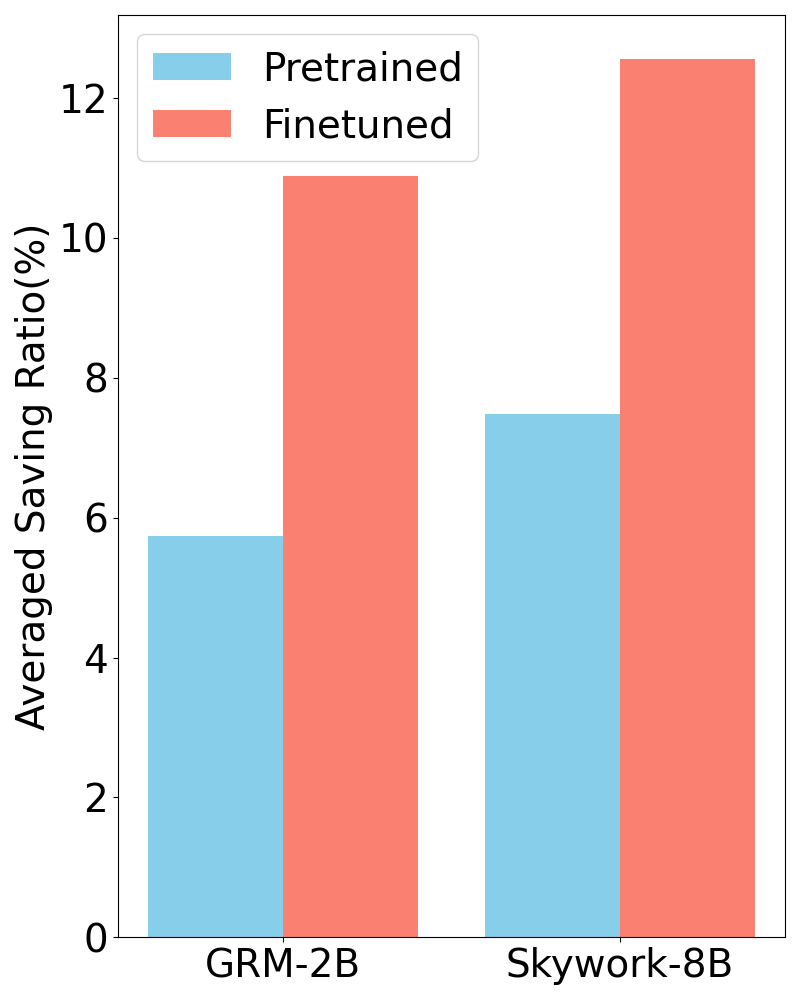
Figure 1: (Left) Control Variates Evaluation makes use of a possibly inaccurate synthetic evaluator to reduce the variance of evaluation, reducing the need of human annotations while preserving unbiasedness. (Right) Averaged mean square error v.s. number of human annotations for Human Evaluation, Synthetic Evaluation and Control Variates Evaluation using the finetuned Skywork-8B evaluator on Chatbot Arena. The Synthetic Evaluation has high bias, while the bias of Human and Control Variates Evaluations are negligible. Control Variates Evaluation reduces the variance of Human Evaluation.