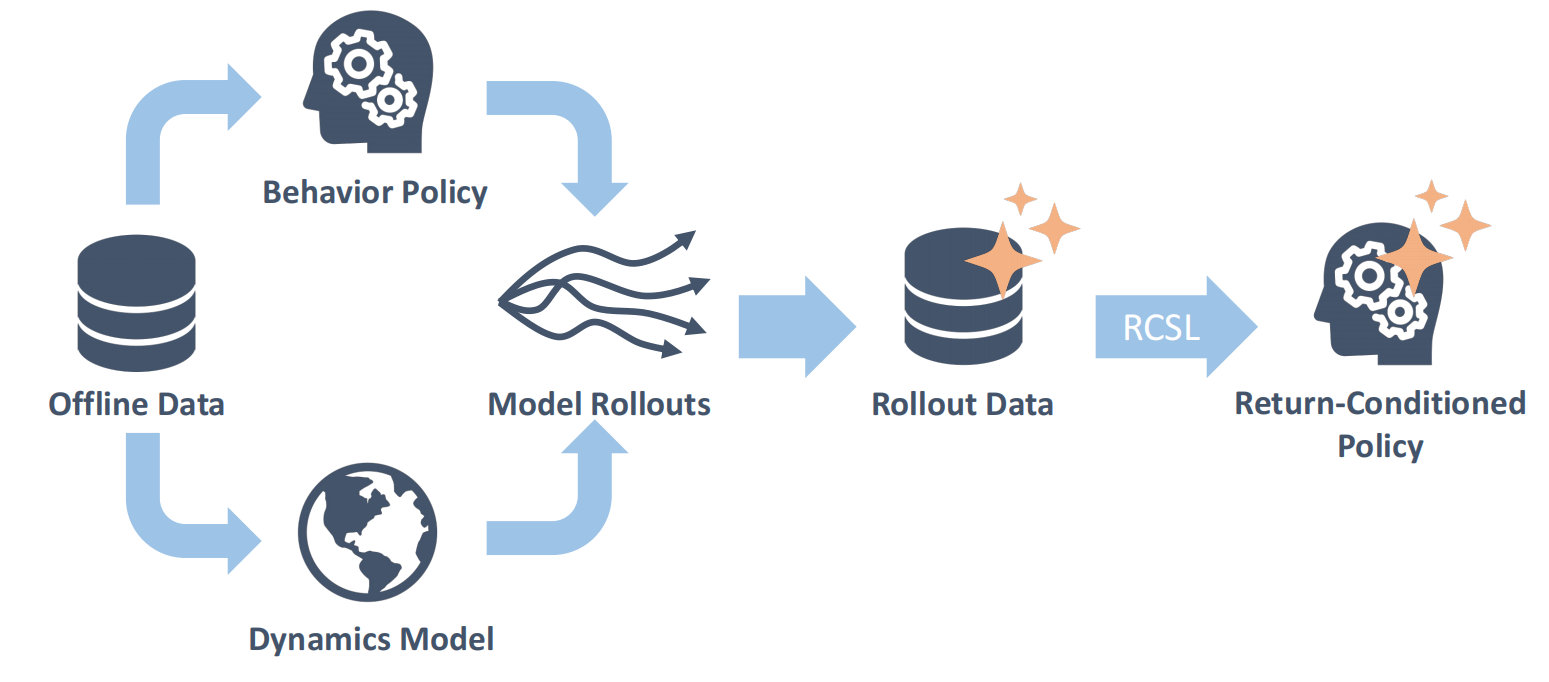
Overview
Background
Off-policy dynamic programming (DP) techniques such as Q-learning are not guaranteed to converge in the presence of function approximation, often diverging due to the absence of Bellman-completeness in the function classes considered.
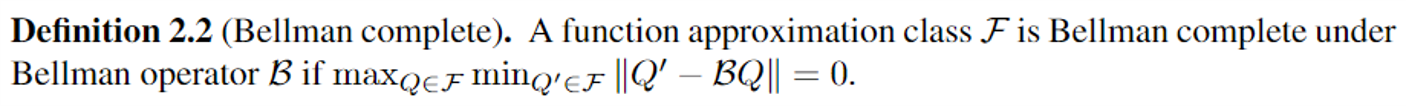
Return-conditioned supervised learning (RCSL) is an alternative off-policy framework, which learns a return-conditioned distribution of actions in each state by directly applying supervised learning on the trajectories in the dataset, achieving satisfactory performance by simply conditioning the policy on high desired returns.

Strength of RCSL: Freedom from Bellman Completeness
RCSL is able to circumvent these challenges of Bellman completeness, converging under significantly more relaxed assumptions inherited from supervised learning than DP-based methods. We prove there exists a natural environment in which if one uses two-layer multilayer perceptron as the function approximator, the layer width needs to grow linearly with the state space size to satisfy Bellman-completeness while a constant layer width is enough for RCSL.
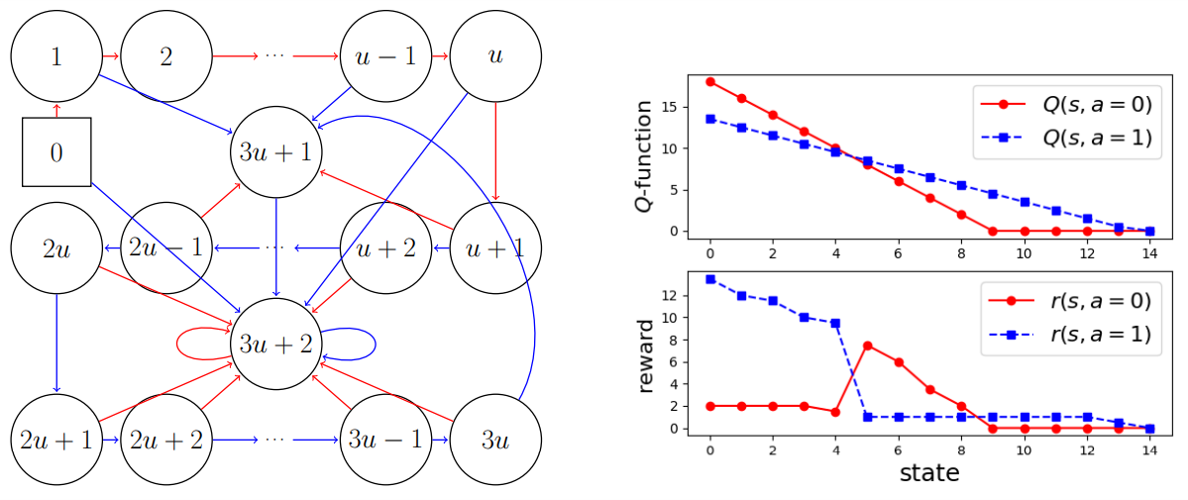
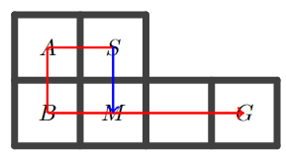
Weakness of RCSL: No Trajectory Stitching
For either special case of RCSL:
- Markovian RCSL (context length equal to 1);
- Decision transformer (using cross-entropy loss) with any context length,
- Deterministic transition;
- Uniform coverage of dataset.